The term "environment" as used in this document refers to a directory on the server, such as /etc/puppetlabs/code/environments/<name>, containing puppet manifests, hiera data, custom facts, etc.
At the beginning of an agent run, the agent and server negotiate which environment to use. It is important for the agent and server to use the same environment during the run, because the manifest may reference facts that must be downloaded and evaluated on the agent. If they are mismatched, then compilation can fail.
For security reasons, puppet defaults to server-specified environments. This means the server always decides which environment to assign to each agent. This is important because we don't want an agent to request a catalog from an arbitrary environment, as the server might include a class containing sensitive data.
However, there are cases during iterative development where it is necessary for a trusted user to be able to run the agent against an environment contained in a feature branch. For example, puppet agent -t --environment <feature>. If the code works as intended, then it provides confidence that the feature branch code can be merged. We refer to this workflow as an agent-specified environment.
The server decides which environment an agent should use by asking its node terminus to classify the node. Terminus just means there's an implementation of an interface that knows how to perform CRUD operations on Puppet::Node objects. The terminus is responsible for returning a node object, including the environment that the node is assigned to.
PE ships with a classifier node terminus that communicates with the PE classifier via REST. So by default, PE uses server-specified environments.
However, open source defaults to a plain node terminus, which means it falls back to agent-specified environments.
When the agent negotiates with the server, the server may respond in one of the following ways:
- Tell the agent to switch to the server-specified environment.
- Allow the agent to continue using its current agent-specified environment.
- Fail the run due to a classification conflict. Conflicts can arise if the agent is assigned to multiple environments at the same time, as can happen if the agent's facts match multiple rules in the classifier.
- Fail the request because the agent's requested environment doesn't exist on the server.
If the agent starts off in the correct environment at the start of its run and it uses that environment for the duration of the run, then the agent and server environments are synchronized.
The process of trying to synchronize environments is referred to as environment convergence.
When running in a server-specified context, i.e. the server always decides which environment to use, then the agent's run should result in one of the following outcomes (ignoring networking issues, etc):
- If the agent's environment is synchronized with the server, then the agent uses that environment for the duration of the run.
- If the environments are not synchronized, then the server will attempt to switch the agent to the server-specified environment. The agent will retry its run using the server-specified environment, up to some maximum retry limit.
- If the environment does not converge after N retries, then the agent fails the run. This can happen if classification rules cause the environment to flap from environment A to B to A, etc.
There are several reasons why environments may not be synchronized:
- The agent has never run before or its cache directory was deleted.
- The agent was configured to use a different environment on the command line or puppet.conf than it used last time.
- Classification changed on the server.
- A fact's value changed on the agent and classification is based on the fact.
- The environment was updated on the server, such as modifying a fact used in classification.
- The environment was deleted on the server.
In all cases, the server will attempt to switch the agent to a "known good" environment. For example, if agents are configured to use an environment, but it is deleted from the server, then we want those agents to reconverge to a new server-specified environment. This self-healing property is important when running agents at scale.
When running in an agent-specified context, i.e. the server allows the agent to decide, then the agent's run may result in one of the following outcomes (again ignoring networking issues):
- If the environment exists on the server, then the agent will use that for the duration of the run, even if it needs to download facts and plugins from the server.
- If the environment doesn't exist on the server:
- By default, switch to the server-specified environment, typically the value of
Puppet[:environment]on the server. - Otherwise, if
strict_enviroment_modeis enabled, then fail the run, because the user wants to strictly use the requested environment.
Prior to 6.25.0 and 7.10.0, the agent used to make a node request at the beginning of the run to determine which environment to start off in. This was changed in PUP-10216 so the agent will start off in the environment it used last time. This information is stored in Puppet[:lastrunfile]. Doing so eliminates the agent's node request and several requests among server, classifier, puppetdb and postgres.
The old behavior can be enabled using the Puppet[:use_last_environment]=false setting or specifying --no-use_last_environment on the command line.
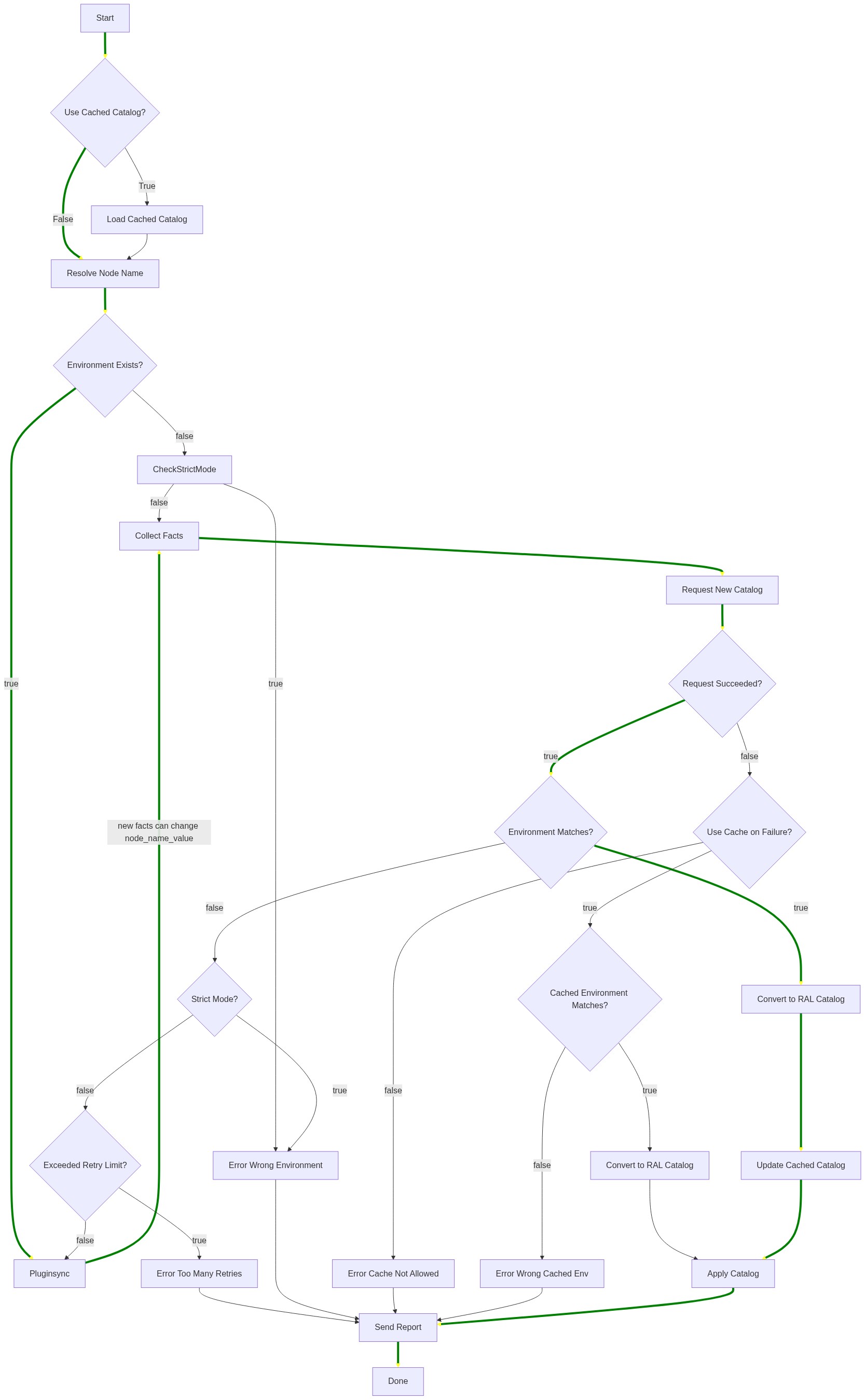
The following flow diagram shows how the agent converges its environment. The green lines trace the happy path: