The goal of this project is to apply reseach papers on a Minecraft bot to resolve different tasks.
>> cd C:\Users\avillemin\Pictures\Malmo-0.36.0-Windows-64bit_withBoost_Python3.6\Minecraft
>> launchClient.batEnvironment used : https://github.com/Microsoft/malmo


As expected, the result is not very good. Why? Because there is only a positive reward when the Agent reaches the final blue block. The problem is that it happens very few because the agent falls into the lava before. So the sample when the agent reaches the positive reward represents less than 1% of the samples with a random policy. As I'm using samples randomly selected from the memory to train my model, the agent doesn't learn correctly the case when the positive reward occurs. All the Q-values predicted are negative. To deal with this issue, we need to use a memory with Prioritized Experience Replay.
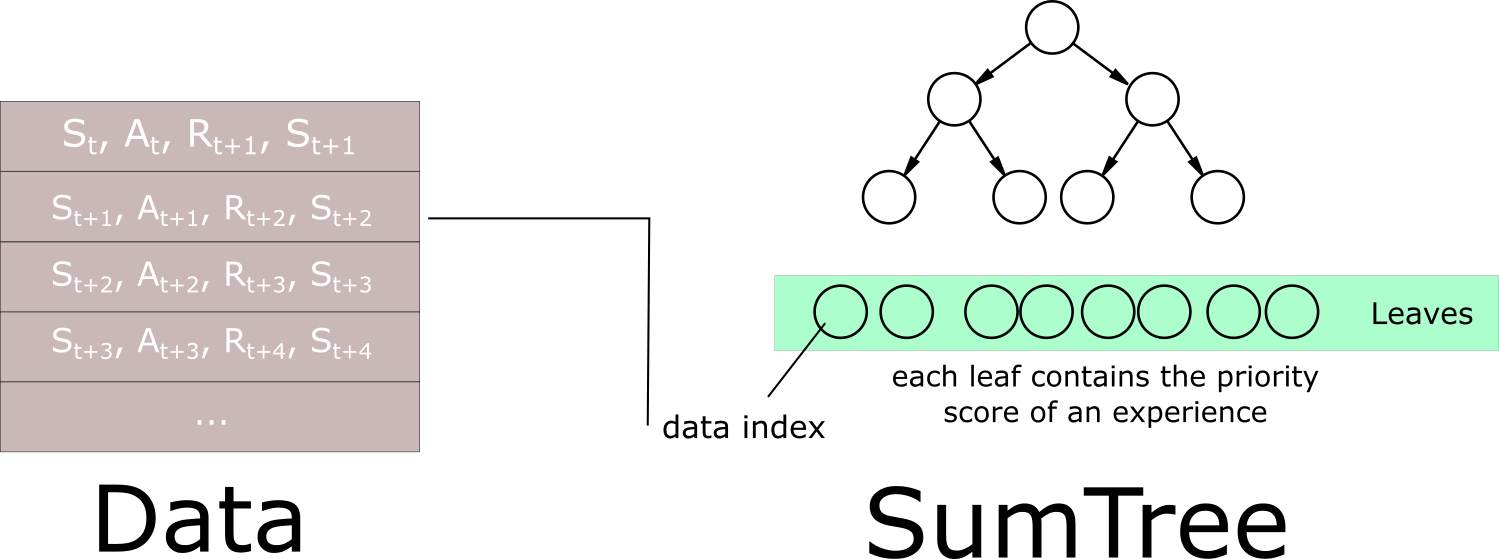
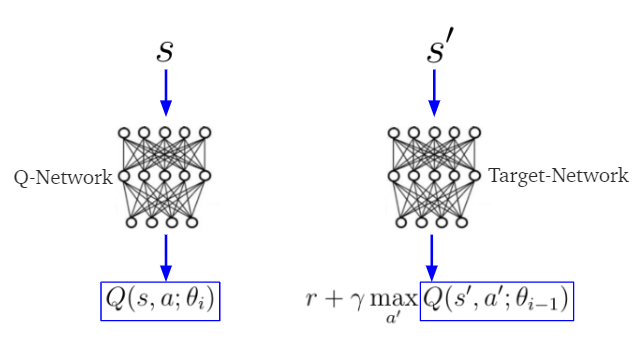
With Prioritized Experience Replay, the network is focusing more on the final positive reward.


The Minecraft environment is very heavy and the game easily runs out of memory with a long training. My approach to deal with this issue is to create a World Model. By creating a neural network able to dream and play Minecraft without the environment, we can easily improve the learning and parallelize the process. First, let's create a variational autoencoder able to encode our input images into a smaller vector:

Here is the result of the VAE with the original image and the reconstructed image:
